Kalau kamu sedang mengikuti perkembangan AI, khususnya dibidang LLM seperti ChatGPT yang sedang populer, pasti sering dengar konsep Retrieval-Augmented Generation atau sering disebut RAG. Kali ini, kita akan membahas konsep tersebut dan melihat bagaimana cara implementasinya.
Sebeneranya, ada beberapa framework populer yang membantu developer dalam pengembangan aplikasi RAG, seperti: LangChain atau LlamaIndex. Namun, di sini kita akan mengambil pendekatan yang berbeda.
Alih-alih terjebak dengan berbagai library atau framework populer yang sering kali menambah lapisan abstraksi, kita akan fokus pada implementasi yang lebih mendasar. Kenapa ini penting? Karena dengan menghindari tools yang sudah ada, kita bisa lebih memahami inti dari konsep yang kita bahas dan bagaimana prinsip-prinsip dasarnya bekerja.
Retrieval-Augmented Generation
RAG hanya merupakan satu dari beberapa metode atau architectural approach untuk meningkatkan akurasi dan relevansi LLM. Ada beberapa metode lain seperti Fine-Tuning, Prompt Engineering dan lainnya, namun kali ini kita akan fokus untuk pembahasan RAG.
Oke, mari kita mulai pembahasannya. Sekarang, kita kesampingkan dulu bagian “Retrieval-Augmented” dan fokus pada kata “Generation”. Generation di sini merujuk pada kemampuan LLM untuk menghasilkan teks sebagai respons terhadap query atau prompt dari pengguna. Namun, terkadang model-model ini menunjukkan behavour yang tidak diinginkan. Mengapa ini bisa terjadi? Karena pada model tradisional, respons yang dihasilkan hanya terbatas berdasarkan pola dan informasi yang telah dipelajari selama fase training. Ada beberapa problem yang mungkin bisa timbul:
- Kedaluwarsa: Model mungkin memberikan informasi yang sudah tidak relevan atau ketinggalan zaman karena data pelatihan yang digunakan tidak mencakup perkembangan terbaru.
- Keterbatasan Konteks: Model mungkin tidak memahami konteks penuh dari query pengguna, sehingga respons yang dihasilkan tidak sepenuhnya tepat.
Baik, mari kita coba dan praktikkan bagaimana model memiliki keterbatasan konteks. Dalam contoh ini, penulis menggunakan model gpt-4o-mini dari OpenAI dan memanfaatkan bahasa pemrograman Golang untuk demonstrasinya.
Mari kita buat fungsi untuk melakukan generate chat completion dengan menggunakan OpenAI API. Fungsi ini akan menerima sebuah string prompt yang berisi input query dan mengembalikan respons teks.
package main
const OPENAI_API_KEY = "your_openai_api_key"
func getCompletion(userPrompt string) (string, error) {
url := "https://api.openai.com/v1/chat/completions"
systemPrompt := "Kamu adalah asisten yang membantu"
payload, _ := json.Marshal(map[string]any{
"model": "gpt-4o-mini",
"temperature": 0.7,
"messages": []map[string]any{
{"role": "system", "content": systemPrompt},
{"role": "user", "content": userPrompt},
},
})
req, err := http.NewRequest(
http.MethodPost,
url,
bytes.NewBuffer(payload),
)
if err != nil {
return "", err
}
req.Header.Set("Content-Type", "application/json")
req.Header.Set("Authorization", fmt.Sprintf("Bearer %s", OPENAI_API_KEY))
resp, err := http.DefaultClient.Do(req)
if err != nil {
return "", err
}
defer resp.Body.Close()
body, err = io.ReadAll(resp.Body)
if err != nil {
return "", err
}
if resp.StatusCode >= http.StatusBadRequest {
return "", fmt.Errorf("http request not returned ok")
}
var r struct {
Choices []struct {
Message struct {
Content string `json:"content"`
} `json:"message"`
} `json:"choices"`
}
err = json.Unmarshal(body, &r)
if err != nil {
return "", err
}
if len(r.Choices) == 0 {
return "", fmt.Errorf("no choices found in response")
}
return r.Choices[0].Message.Content, nil
}
Mari kita coba tanya ke OpenAI terkait siapa presiden Indonesia yang sekarang.
package main
func main() {
resp, err := getCompletion("Siapakah presiden Indonesia saat ini?")
if err != nil {
panic(err.Error())
}
fmt.Println(resp.Choices[0].Message)
}
Respons:
Presiden Indonesia saat ini adalah Joko Widodo. Ia mulai menjabat pada 20 Oktober 2014 dan terpilih kembali untuk masa jabatan kedua pada pemilihan umum 2019.
Pada saat penulisan blog ini, yaitu tanggal 28 Oktober 2024, posisi Presiden Indonesia sudah tidak lagi dipegang oleh Joko Widodo. Untuk meningkatkan keakuratan pertanyaan yang diajukan kepada model, mari kita ubah promptnya agar lebih spesifik dengan menyebutkan tahun.
package main
func main() {
...
resp, err := getCompletion("Siapakah presiden Indonesia 2024?")
...
}
Respons:
Saya tidak memiliki informasi tentang siapa yang menjadi presiden Indonesia pada tahun 2024, karena pengetahuan saya terbatas hingga Oktober 2021. Untuk mengetahui siapa presiden Indonesia pada tahun 2024, Anda perlu merujuk pada sumber berita terbaru atau informasi terkini.
Dari jawaban tersebut kita bisa tahu bahwa model ini memiliki keterbatasan dalam memberikan informasi terkini karena data pelatihannya hanya mencakup pengetahuan hingga Oktober 2021. Dengan keterbatasan seperti ini, jawaban yang diberikan tidak selalu sesuai dengan perkembangan terbaru.
Sebelum kita membahas lebih jauh tentang RAG, penulis ingin memberikan contoh bagaimana menambahkan konteks secara manual ke dalam system prompt. Misalnya, ketika kita mengajukan pertanyaan kepada OpenAI seperti, ‘Siapa Presiden Indonesia tahun 2024?’, kita sebenarnya bisa memperkaya konteks pertanyaan itu dengan menambahkan informasi latar belakang. Dengan cara ini, kita dapat meningkatkan peluang mendapatkan jawaban yang lebih tepat atau relevan. Mari kita lihat bagaimana konteks ini bisa mempengaruhi respons yang diberikan oleh model.
Kita coba untuk mengambil beberapa informasi dari situs web presidenri.go.id dan menaruhnya ke dalam sistem prompt.
package main
func getCompletion(userPrompt string) (string, error) {
...
systemPrompt := `
Kamu adalah asisten yang membantu.
Gunakan konteks berikut ini untuk menjawab pertanyaan.
Jika Kamu tidak tahu jawabannya, katakan bahwa Kamu tidak tahu.
Pasangan Jenderal TNI (Purn) Prabowo Subianto dan Gibran Rakabuming Raka
secara resmi mengemban tugas sebagai Presiden dan Wakil Presiden Republik Indonesia
masa jabatan 2024-2029 pada Minggu, 20 Oktober 2024.
Keduanya dilantik dalam Sidang Paripurna Majelis Permusyawaratan Rakyat (MPR)
dalam rangka Pelantikan Presiden dan Wakil Presiden Masa Jabatan 2024-2029
yang diselenggarakan di Gedung Nusantara MPR/DPR/DPD RI, Jakarta.`
...
}
Respons:
Presiden Indonesia 2024 adalah Jenderal TNI (Purn) Prabowo Subianto.
Akhirnya kita mendapatkan jawaban yang sesuai dengan improvisasi yang telah kita lakukan pada prompt sistem, dan bonusnya, kita juga berhasil mengurangi jawaban yang tidak relevan atau yang sering disebut sebagai hallucination dalam LLM dengan memberikan perintah untuk menyatakan ketidaktahuan jika informasi tidak tersedia. Namun, ada beberapa kelemahan dengan metode yang kita lakukan:
- Keterbatasan Kapasitas: Prompt yang terlalu panjang atau kompleks dapat melebihi batas kapasitas yang dapat diproses oleh model. Ini dapat menyebabkan informasi penting terlewat atau terdistorsi, yang berdampak negatif pada kualitas respons. Selain itu, penggunaan prompt yang lebih panjang juga berarti penggunaan lebih banyak token, yang dapat meningkatkan biaya apabila kita menggunakan model berbayar seperti OpenAI.
- Kurangnya Fleksibilitas: Mengandalkan penambahan konteks secara manual membuat prompt kurang fleksibel. Jika informasi yang diperlukan berubah, prompt harus diubah secara manual setiap kali, yang bisa menjadi tidak praktis.
Maka dari itu, kita akan menggunakan RAG untuk mengatasi keterbatasan ini. Dengan RAG, model dapat mengakses dan menarik informasi terbaru dari sumber eksternal, mengurangi ketergantungan pada konteks manual yang statis. Selain itu, RAG memanfaatkan embedding vektor yang memungkinkan pencarian informasi lebih efisien dan relevan.
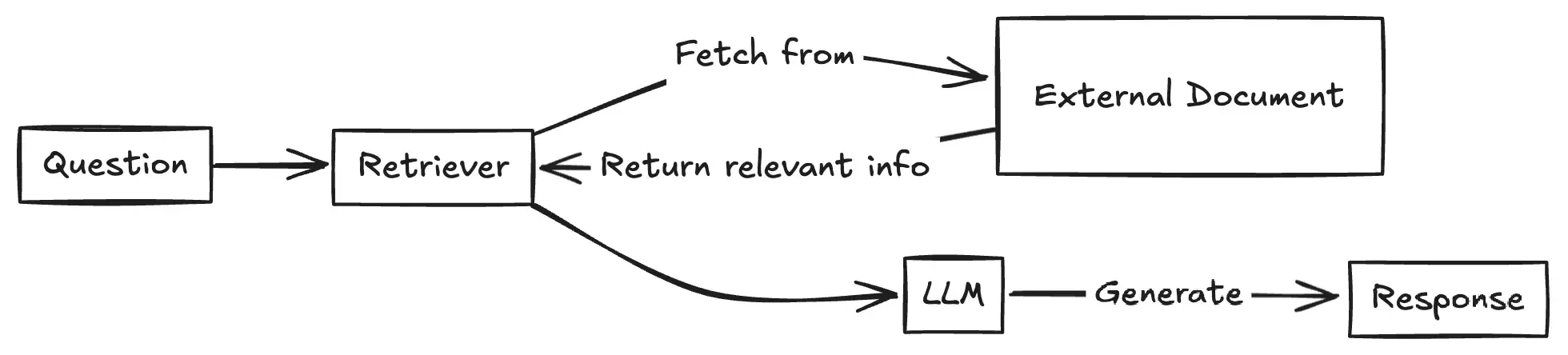
Pada diagram diatas, RAG akan meningkatkan kemampuan model dengan mengintegrasikannya dengan mekanisme pencarian. Secara keseluruhan, proses ini terdiri dari dua komponen penting: Retriever dan Generator.
Komponen Retriever
Komponen ini bertugas untuk mencari dokumen atau bagian informasi dari input query ke database. Ada dua jenis retrievers:
- Dense: Menggunakan metode neural network untuk membuat teks embedding. Biasanya dipakai apabila makna dari teks lebih penting daripada exact kata, karena embedding yang dipakai menangkap kesamaan semantik.
- Sparse: Kebalikannya, metode ini unggul dalam pencarian exact kata, yang bisa sangat berguna ketika query berisi istilah yang unik atau rare.
Pemilihan jenis retriever sangat tergantung kepada database dan ekspektasi querynya. Pada praktik kali ini kita akan menggunakan Dense Retriever.
Komponen Generator
Komponen ini bertugas memberikan respons yang relevan dari input query dengan tambahan konteks yang didapat dari retiever.
Workflow Sistem RAG
Sebelum ke detail workflownya, kita akan memanfaatkan model dari OpenAI yaitu text-embedding-3-small untuk membuat embedding dari dokumen atau informasi yang kita dapat. Hasil embedding tersebut kemudian akan disimpan di PostgreSQL sebagai database vektor. Data ini nantinya akan digunakan oleh retriever untuk melakukan pencarian. Pada praktek kali ini kita akan langsung mengirim semua teks dari tautan berita sebelumnya ke OpenAI.
Pertama, kita akan membuat fungsi baru yang bertugas untuk generate embedding, fungsi ini akan menerima input string dan mengembalikkan data vektor.
package main
func generateEmbeddings(input string) ([]float32, error) {
url := "https://api.openai.com/v1/embeddings"
payload, _ := json.Marshal(map[string]any{
"input": input,
"model": "text-embedding-3-small",
})
req, err := http.NewRequest(
http.MethodPost,
url,
bytes.NewBuffer(payload),
)
if err != nil {
return nil, err
}
req.Header.Set("Content-Type", "application/json")
req.Header.Set("Authorization", fmt.Sprintf("Bearer %s", OPENAI_API_KEY))
resp, err := http.DefaultClient.Do(req)
if err != nil {
return nil, err
}
defer resp.Body.Close()
body, err := io.ReadAll(resp.Body)
if err != nil {
return nil, err
}
if resp.StatusCode >= http.StatusBadRequest {
return nil, fmt.Errorf("http request not returned ok: %s", string(body))
}
var r struct {
Data []struct {
Embedding []float32 `json:"embedding"`
} `json:"data"`
}
err = json.Unmarshal(body, &r)
if err != nil {
return nil, err
}
if len(r.Data) == 0 {
return nil, fmt.Errorf("no data found in response")
}
return r.Data[0].Embedding, nil
}
Di real case, kamu bisa mengekstrak teks dari beberapa sumber seperti PDF, WordPress, Markdown dll. Namun, kali ini kita akan melewatkan proses ekstraksi teks for simplicity. Penting untuk diingat bahwa ukuran dan kompleksitas dokumen dapat mempengaruhi kualitas embedding yang dihasilkan, sehingga kita perlu menerapkan fungsi text splitter untuk memecah teks menjadi bagian-bagian kecil atau disebut chunk.
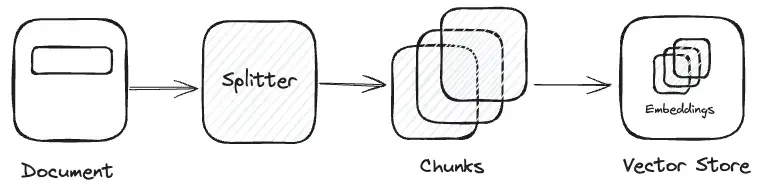
Chunk ini menyelesaikan masalah yang kita hadapi sebelumnya ketika kita harus menambahkan semua konteks secara manual di sistem prompt, yang bisa menyebabkan biaya tokenisasi tinggi dan hasil yang kurang optimal. Namun, kali ini kita tidak akan membuat metode text splitter yang kompleks. Sebagai gantinya, kita cukup memecah teks menjadi chunk dengan memisahkan input berdasarkan pemisah paragraf baru, yaitu \n\n.
Kita coba menyalin semua teks pada website sebelumnya, dan memasukannya sebagai input parameter.
package main
func main() {
...
input := `Pasangan Jenderal TNI (Purn) Prabowo Subianto dan Gibran Rakabuming Raka
secara resmi mengemban tugas sebagai Presiden dan Wakil Presiden Republik Indonesia
masa jabatan 2024-2029 pada Minggu, 20 Oktober 2024.
...
... (omitted for spacing)`
chunks := strings.Split(input, "\n\n")
for _, chunk := range chunks {
embedding, err := generateEmbeddings(chunk)
if err != nil {
panic(err.Error())
}
fmt.Println(embedding)
}
}
Respons:
[
-0.022393186,
-0.037375677,
0.007688148,
0.016163906,
... (omitted for spacing)
0.01099969
]
Selanjutnya, kita akan menyimpan hasil embedding ke dalam database. Untuk melakukan ini, kita akan menyiapkan pgvector, sebuah open-source library untuk vector similarity search di PostgreSQL. Instalasi lengkap dapat dilihat pada link repository.
Setelah berhasil menjalankan database, langkah pertama adalah mengaktifkan ekstensi vector dengan perintah berikut:
CREATE EXTENSION vector;
Kemudian, buat tabel yang berisi kolom vektor dengan dimensi sesuai kebutuhan. By default, dimensi dari model text-embedding-3-small adalah 1536:
CREATE TABLE documents (
id SERIAL PRIMARY KEY,
text TEXT,
embedding vector(1536)
);
Sebelum melanjutkan ke langkah berikutnya, ada dua library yang perlu kita instal supaya proyek Go kita dapat berinteraksi dengan PostgreSQL dan ekstensi vektornya.
go get github.com/lib/pq
go get github.com/pgvector/pgvector-go
Selanjutnya, kita akan membuat fungsi untuk inisialisasi instance database dan insert embedding ke dalamnya.
package main
func initDB() (*sql.DB, error) {
// Replace with your actual connection details
connStr := "postgres://username:password@localhost/dbname?sslmode=disable"
db, err := sql.Open("postgres", connStr)
if err != nil {
return nil, err
}
if err := db.Ping(); err != nil {
return nil, err
}
return db, nil
}
func insertEmbedding(db *sql.DB, text string, embeddings []float32) error {
sql := "INSERT INTO documents (text, embedding) VALUES ($1, $2)"
_, err := db.Exec(sql, text, pgvector.NewVector(embeddings))
if err != nil {
return err
}
return nil
}
Dan akhirnya, kita akan memasukan data embedding yang sebelumnya telah berhasil kita generate dari OpenAI ke database.
package main
func main() {
...
input := `Pasangan Jenderal TNI (Purn) Prabowo Subianto dan Gibran Rakabuming Raka
secara resmi mengemban tugas sebagai Presiden dan Wakil Presiden Republik Indonesia
masa jabatan 2024-2029 pada Minggu, 20 Oktober 2024.
...
... (omitted for spacing)`
embedding, err := generateEmbeddings(input)
if err != nil {
panic(err.Error())
}
db, err := initDB()
if err != nil {
panic(err.Error())
}
err = insertEmbedding(db, input, embeddings)
if err != nil {
panic(err.Error())
}
}
Setelah kita berhasil menyiapkan database vektor yang akan dikonsumsi oleh retriever, kita akan membahas secara rinci workflow RAG yang akan diimplementasikan. Let’s go!
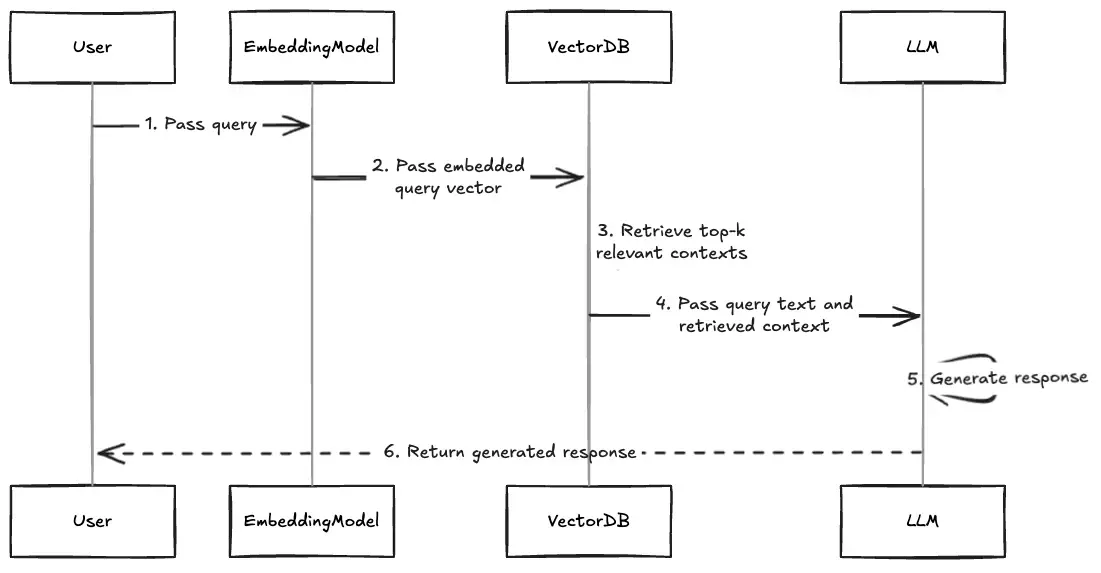
Kita akan run through setiap langkah yang terdapat dalam diagram di atas secara menyeluruh, sambil melakukan praktik implementasinya.
1. Pass Query
Proses dimulai ketika User mengirimkan query ke sistem. Pada tahap awal, query masih dalam bentuk teks mentah yang perlu diproses lebih lanjut agar dapat digunakan oleh sistem.
package main
func main() {
...
query := "Siapakah presiden Indonesia 2024?"
}
2. Pass embedded query vector
Selanjutnya, EmbeddingModel mengambil peran penting dalam mengubah query teks menjadi representasi vektor numerik. Mengapa kita perlu mengubah pertanyaan user menjadi representasi vektor? Karena, kita akan melakukan similarity search ke dokumen yang telah kita embed ke database seebelumnya.
package main
func main() {
...
query := "Siapakah presiden Indonesia 2024?"
queryEmbeddings, err := generateEmbeddings(query)
if err != nil {
panic(err.Error())
}
}
3. Retrieve top-k relevant contexts
Setelah query diubah menjadi vektor, VectorDB mengambil alih proses pencarian. Database vektor ini menyimpan koleksi besar dokumen yang sudah di-embedding sebelumnya dan menggunakan algoritma similarity search untuk menemukan dokumen-dokumen yang paling relevan.
Mari kita buat fungsi baru untuk melakukan similarity search dengan menggunakan database vektor yang telah kita buat. Fungsi ini akan mengambil vektor query sebagai input dan mengembalikan maksimal dua dokumen teratas yang paling relevan.
package main
func similaritySearch(db *sql.DB, queryEmbeddings []float32) ([]string, error) {
sql := "SELECT text FROM documents ORDER BY embedding <-> $1 LIMIT 2"
rows, err := db.Query(sql, pgvector.NewVector(queryEmbeddings))
if err != nil {
return nil, err
}
defer rows.Close()
var results []string
if rows.Next() {
var text string
if err := rows.Scan(&text); err != nil {
return nil, err
}
results = append(results, text)
}
return results, nil
}
4. Pass query text and retrieved context
VectorDB kemudian mengirimkan hasil temuannya ke LLM, yang terdiri dari query asli dan konteks relevan yang ditemukan. Konteks ini sudah diurutkan berdasarkan relevansi dan dikirim dalam format prompt terstruktur yang siap diproses.
5. Pass query text and retrieved context
Pada tahap berikutnya, LLM memproses kombinasi query dan konteks menggunakan arsitektur neural network yang kompleks. LLM tidak hanya mengandalkan pengetahuan yang sudah ada dalam modelnya, tetapi juga memanfaatkan konteks spesifik yang diberikan untuk menghasilkan jawaban yang lebih tepat.
Mari kita update fungsi get completions yang sebelumnya agar dapat menerima konteks dari retriever.
package main
func getCompletion(userPrompt string, contexts []string) (string, error) {
url := "https://api.openai.com/v1/chat/completions"
systemPrompt := fmt.Sprintf(`
Kamu adalah asisten yang membantu.
Gunakan konteks berikut ini untuk menjawab pertanyaan.
Jika Kamu tidak tahu jawabannya, katakan bahwa Kamu tidak tahu.
%s`, strings.Join(contexts, "\n"))
...
}
Terakhir, kita akan execute request ke OpenAI untuk mendapatkan jawaban berdasarkan kombinasi query dan konteks yang telah kita siapkan. Ini akan melibatkan semua step sebelumnya, mulai dari mengubah query teks menjadi representasi vektor, melakukan similarity search, hingga meneruskan hasil tersebut ke fungsi get completions sebagai konteks untuk mendapatkan respons yang diinginkan.
package main
func main() {
query := "Siapkah presiden indonesia 2024?"
embeddings, err := generateEmbeddings(query)
if err != nil {
panic(err.Error())
}
db, err := initDB()
if err != nil {
panic(err.Error())
}
contexts, err := similaritySearch(db, embeddings)
if err != nil {
panic(err.Error())
}
resp, err := getCompletion(query, contexts)
if err != nil {
panic(err.Error())
}
fmt.Println(resp)
}
Respons:
Presiden Indonesia untuk masa jabatan 2024-2029 adalah Jenderal TNI (Purn) Prabowo Subianto, yang akan dilantik pada 20 Oktober 2024.
6. Pass query text and retrieved context
Akhirnya, sistem mengirimkan respons yang telah dihasilkan kembali ke user.
Penutup
Tentu, masih banyak yang bisa kita tingkatkan dari praktik yang sudah dilakukan agar aplikasi benar-benar siap untuk digunakan di lingkungan production. Fokus utama kita adalah merancang pipeline RAG dengan langsung menguraikan komponen-komponen pentingnya dan meminimalkan lapisan abstraksi yang ada pada beberapa framework. Source code lengkapnya bisa dilihat di https://github.com/syahidfrd/rago.